유용한 JVM 플래그들 – Part 5 (Young Generation Garbage Collection)
이번 시간에 우리는 주요한 힙 영역의 하나인 “young generation” 에 집중한다. 첫째로, 우리는 우리의 애플리케이션의 성능에 아주 중요한 young generation의 알맞은 설정이 무엇인지 논의한다. 그리고나서 우리는 적절한 JVM 플래그들에 대해서 알아보도록 하자.
순수하게 기능적인 관점에서, JVM은 young generation 을 전혀 필요하지 않는다. – 그것은 하나의 힙 영역으로만으로도 동작한다. 첫위치에 young generation 을 가져야할 유일한 이유는 가비지 컬랙션(Garbage Collection, GC) 성능을 최적화하는데 있다. 구체적으로, young generation 과 old generation 으로 힙의 분리는 두가지 장점을 가진다. 새로운 객체의 할당을 간소화해주고 (왜냐하면 메모리 할당은 young generation 에 영향을 주기 때문) 더 이상 필요하지 않은 객체를 좀 더 효과적으로 클린업 해준다.(두 generation 에 서로 다른 GC 알고리즘을 사용해)
객체 지향 프로그램의 넓은 범위에 걸쳐 광범위 측정은 많은 응용 프로그램이 공통 특성을 공유하는 것으로 나타났다: 대부분의 객체는 젊었을때 죽는다. 예를들어 그들이 생성되고 난 후에 프로그램 흐름상 오랫동안 참조(reference) 되지 않았을때. 또, 이것은 젊은 객체들은 좀 더 늙은 객체들에 드물게 참조되어졌다는 것이 관찰되었다. 지금바로 우리가 이러한 두가지 관점을 조합한다면, GC가 young 객체에 빠른 접근을 가질수 있도록 하는것이 바람직하다는게 분명해 진다. – 예를들어 이 힙 영역안에 “young generation” 으로 불리우는 분리된 힙 영역에서, GC 는 그들을 판별할 수 있고 오랜시간동안 힙에서 여전히 살고 있는 모든 old 객체들사이에서 그들을 찾을 필요없이 빠르게 죽은 young 객체를 수집한다.
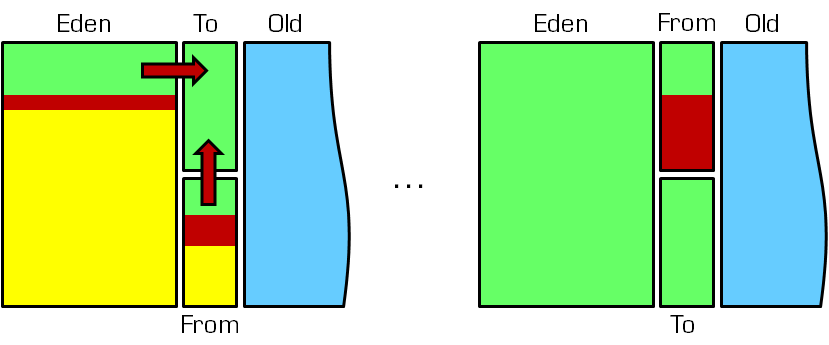
더나가 Sun/Oracle HotSpot JVM은 young generation은 세개의 서브 영역들로 나뉜다: “Eden” 으로 이름붙여진 하나의 큰 영역과 “From”과 “To”로 이름붙여진 두개의 좀 더 작은 “survivor spaces”. 규칙처럼, 새로운 객체는 “Eden”에 할당되이진다. (예외적으로 만약 새로운 객체가 “Eden” 공간에 들어가기에 너무나 크다면 old generation 에 직접 할당되어진다) GC 동안, “Eden”에 살아있는 객체들은 첫째로 survivor 영역으로 이동되고 그들이 특정한 시점에 도달할때까지 그곳에 머물고나서 (in terms of numbers of GCs passed since their creation) old generation 으로 전달된어진다. 따라서, survivor 영역의 롤(role)은 나중에 그들이 죽는 순간에 그들을 빠르게 수집하는게 가능하게 하기위해서 그들의 첫번재 GC보다 좀더 오랫동안 young generation 에 young 객체를 유지시키는 것이다.
대부분의 young 객체들이 GC 중에 삭제되어질 것이라는 사실에 기반해, 복사하기 전략(“copy collection”) 은 young generation GC 를 위해서 사용되어 진다. GC가 시작되면, survivor 공간 “To”는 비어지고 객체들은 오직 “Eden” 혹은 “From”에만 존재할 수 있다. 그때, GC 중에, “Eden”의 여전히 참조되어지고 있는 모든 객체들은 “To”로 이동되어진다. “From” 에서는 이 공간에서 여전히 참조되고 있는 객체들은 그들의 나이에 의존해 다루어진다. 만약 특정 나이에 도달하지 않으면(“tenuring threshold”), 그들 또한 “To”로 이동되지만 그렇지 않은 경우에는(특정한 나이에 도달하면) old generation 으로 이동되어진다. 이 복사하기 과정이 끝날때에, “Eden” 과 “From”은 빈 공간으로 여겨지고(왜냐하면 그들은 오직 죽은 객체들만 가지고 있으니까.) 모든 young generation 에서 살아있는 객체들은 “To”에 있게 된다. GC 중에 특정시점에 “To”를 채워야하는데, 남아 있는 모든 객체들은 old generation 으로 이동된다.(그리고 결코 되돌아오지 않는다). 마지막으로, “To”가 다음 GC에 다시 비워지고 “From”이 모든 남은 young 객체들을 가지고 있기 위해서 “From”과 “To”는 그들의 롤들을 바꾼다.(더 정확하게는 그들의 이름을 바꾼다.)
이제 young generation 크기가 왜 중요한지 확실해졌다. 만약 young generation 이 아주 작으면, 짧게 생존하는 객체들은 그들이 수집되기 좀 더 힘든 old generation 으로 빠르게 옮겨진다. 반대로 young generatin이 아주 크면, 우리는 어쨌거나 나중에 old generation 으로 옮겨지게될 오랫동안 생존한 객들을에대해서 불필요하게 아주 많은 복사가 이루어진다. 따라서 우리는 작은 young generation 크기 와 큰 young generation 크기 사이에 접점을 찾을 필요가 있다. 불행하게도, 특정한 애플리케이션에 대해 올바른 접점 찾기는 의미론적 측정과 튜닝에 의해서만 이루어진다. 그리고 그것은 JVM 플래그 설정으로 된다.
-XX:NewSize and -XX:MaxNewSize
전체 힙 크기와 유사하게(-Xms and -Xmx 가지는) 이것도 young generation 의 크기의 양을 명시적으로 하한과 상한으로 지정이 가능하다. when setting -XX:MaxNewSize we need to take into account that the young generation is only one part of the heap and that the larger we choose its size the smaller the old generation will be. 이것은 old generation 보다 you gerneration 크기를 좀 더 크게 선택하지 말아야 하는데, 모든 객체들을 young generation 에서 old generation 으로 이동하기 위해 GC가 필요할 경우에 최악의 상황이 된다. 따라서 -Xmx/2 는 -XX:MaxNewSize 에 대한 상한이다.
성능상의 이유로 우리는 -XX:NewSize 플래그를 사용함으로써 young generation 의 초기 크기를 지정할 수 있다. 우리가 어린 개체가 할당되는 속도를 알고 천천히 시간이 지남에 따라 그 크기로 젊은 세대의 성장에 필요한 비용의 일부를 절약 할 수 있는 경우에 유용하다.
-XX:NewRatio
이것은 또한 old generation 의 상대적인 비율로 young generation 크기를 지정하는게 가능하다. 이러한 접근의 잠재적인 이득은 JVM이 런타임으로 전체 힙크기를 동적으로 변경할때에 young generation 은 자동적으로 자라고 줄어든다. -XX:NewRatio 는 old generation 이 young generation 보다 더 크게 지정되도록 해준다. 예를들어, -XX:NewRatio=3 일때 old generation 는 young generation 보다 3배 더 크게 된다. old generation 은 힙의 3/4 을 young generation 은 힙의 1/4 를 얻게 된다.
만일 우리가 young generation 크기의 절대치와 상대치를 혼용한다면, 절대 값들이 늘 우선한다. 아래의 예를 생각해보자.
|
1 |
$ java -XX:NewSize=32m -XX:MaxNewSize=512m -XX:NewRatio=3 MyApp |
이러한 세팅들은, JVM 은 old generation 의 1/3 로 young generation 크기로 유지하기 위해 애쓸테지만 young generation 이 결코 32MB 이하나 512MB 이상을 초과하지 않도록 한다.
절대 또는 상대적인 young generation 크기가 존재한다면 바람직한 일반적인 룰은 없다. 만약 애플리케이션의 메모리 사용량을 잘 알고 있다면, 전체 힙과 young generation 양쪽 모두 고정된 크기로 지정하는 것이 유리할 수 있고 이것은 비율을 지정하는데도 유용할 수 있다. 만약 우리가 조금만 알거나 애플리케이션에 대해서 전혀 아는게 없다면, 이러한 접근은 단순하게 JVM 을 동작하게하고 플래그 주변을 지저분하게 하지 않게 한다. 만약 애플리케이션이 부드럽게 동작한다면, 우리는 아무것도 필요하지 않은 경우 여분의 노력을 하지 않아도된다는 것에 행복해질 수 있다. 그리고 우리는 성능 문제나 OutOfMemoryErrors가 발생하면 우리는 여전히 튜닝을 하기전에 문제의 근본 원인을 좁힐 수 있는 의미있는 일련의 측정이 필요하다.
-XX:SurvivorRatio
플래그 -XX:SurvivorRatio 는 -XX:NewRatio 유사하지만 young generation 내부 영역에 적용된다. -XX:SurvivorRatio 의 값은 두 survivor 공간중 하나에 상대적으로 얼마나 크게 Eden 을 정할건지를 지정한다. 예를들어, -XX:SurvivorRatio=10는 “To”에 비해서 “Eden”이 10배 큰 치수를 가리킨다. (그리고 같은 시점에서 “From”에 비해 10배 크게). 결과적으로, “Eden”은 young generation 에서 10/12 를 가지는 반면에 “To”와 “From”은 각각 1/12 를 가진다. 주목할 것은 두개의 survivor 공간은 늘 같은 크기다.
survivor 공간의 크기가 주는 영향은 무엇일까? survivor 공간은 “Eden”과 비교해서 아주 작다고 가정한다. 그리고 우리는 “Eden”에 새롭게 할당된 객체를 아주 많이 가지고 있다고 생각해보자. 만약 이러한 모든 객체들이 다음번 GC 동안 모두 수집되어질 수 있다면, “Ede”은 다시 비워지고 모든것은 괜찮아진다.하지만, 만약 이러한 young 객체들중에 몇몇이 여전히 참조되어지는 상태라면, 우리는 survivor 공간에 그들을 수용하기 위해 아주 작은 공간을 가진다. 결론적으로, 이러한 대부분의 객체들은(아직도 참조되어지고 있는 객체들) 첫번째 GC 이후에 old generation 으로 옮겨질 겁니다. 이제 반대 상황을 생각해보자. survivor 공간의 크기가 상대적으로 크다고 가정해보자. 그리고 그들은 자신들의 목적을 수행하기 위해서 많은 공간을 가지고 있다면 객체를 수용하기위해서 하나 이상의 GC들을 발생시키지만 여전히 young 객체는 죽는다. 그러나, 아주 작은 “Eden” 공간은 좀 더 빠르게 고갈될 것이고, 실행되는 young generation GC들의 양은 증가한다.
요약하면, 우리는 너무 빠르게 old generation 으로 이동되어지는 짧은 삶을 사는 객체들의 숫자를 최소화하길 원한다. 하지만 우리는 또 young generation GC 시간과 발생 숫자를 최소화하길 원한다. 다시 말해서 우리는 우리들 스스로 애플리케이션의 특성에 따라서 타협점을 찾을 필요가 있다. 알맞은 타협점을 찾기위한 좋은 시작점은 특정 애플리케이션에 객체들의 연령 분포에 대해서 아는 것이다.
-XX:+PrintTenuringDistribution
-XX:+PrintTenuringDistribution 플래그로 우리는 각각 young generation GC 의 survivor 공간에 포함된 모든 객체들의 연령 분포(age distribution)를 출력하게 할 수 있다. 아래 예제를 보면,
|
1 2 3 4 |
Desired survivor size 75497472 bytes, new threshold 15 (max 15) - age 1: 19321624 bytes, 19321624 total - age 2: 79376 bytes, 19401000 total - age 3: 2904256 bytes, 22305256 total |
첫번째 라인은 “To” survivor 공간의 타켓 사용률(target utilization)이 약 75MB 임을 말해준다. 또, old generation 으로 이동되지 전에 객체가 young generation 에 머무는 GC의 수를 나타내는 “임계 보유기간”에 대한 정보도 보여준다. (i.e., 이것이 추진되기 전에 객체의 최대 수명) 이 예제에서, 우리는 현재 “임계 보유기간”은 15이고 최대값도 15임을 알 수 있다.
다음 라인은, “임계 보유기간” 보다 훨씬 어린 각각의 객체, 현재 그 나이를 가지는 모든 객체의 총 바이트 수를 보여준다 (만약 객체가 현재 특정 연령에 대해 존재하지 않는 경우, 그 라인은 생략된다). 예를들어, 약 19MB 는 한번 GC에서 살아남은 양, 약 79KB는 두번 GC로 살아남은 양, 약 3MB는 세번째 GC에서 살아남은양이다. 각 라인에 끝에는, 그 연령(age)에 올라온 모든 객체들의 총 양(byte) 이다. 따라서 , 마지막 라인에 “Total” 값은 “To” survivor 공간에 현재 약 22MB 의 객체 데이터를 포함한다는 것을 가리킨다. “To”의 타켓 사용률(target utilization)은 75MB 이고 현재 “임계 보유기간”은 15, 우리는 현재 young generation GC 로인해서 old generation 으로 승진시켜야할 객체가 없다는 결론을 내릴 수 있다. 이제 다음 GC가 다음과 같은 출력을 이끌어내는 것을 가정해보자.
|
1 2 3 4 5 |
Desired survivor size 75497472 bytes, new threshold 2 (max 15) - age 1: 68407384 bytes, 68407384 total - age 2: 12494576 bytes, 80901960 total - age 3: 79376 bytes, 80981336 total - age 4: 2904256 bytes, 83885592 total |
이전에 보유기간 분포의 출력과 비교해보자. 이전 출력에서 2, 3세대(age) 의 모든 객체들은 여전히 “To” 에 있다. 왜냐하면 우리는 3, 4세대에 대해 같은 양이 출력된것을 정확하게 볼 수 있다.(역, 뭔 소린지… total 값이 비슷하다는 건지) 그래서 우리는 GC로 인해서 “To” 에 있는 특정 객체들이 성공적으로 수집되었다고 결론을 내릴 수 있다. 왜냐하면 현재 우리는 2 세대의 객체가 12MB만 가지고 있는 반면에 이전 출력에서 1세대는 19MB를 가졌었기 때문이다. 마지막으로 우리는 약 68MB의 새로운 객체들은, 1세대 부분에서, 마지막 GC 동안 “Eden” 에서 “To”로 이동되었다는 것을 알 수 있다.
주목할 것은 “To” 에 총 bytes 수는 – 여기서는 거의 84MB – desired number of 75MB 보다 크다. 결론적으로 JVM은 보유기간 임계값(tenuring threshold)을 15에서 2로 줄였고, 그래서 다음 GC에 특정 객체들은 “To”로 강제로 이주될 것이다. 이러한 객체들은 만약 특정시간에 죽게되면 수집되어지거나 여전히 참조되고 있다면 old generation 으로 이동되어진다.
-XX:InitialTenuringThreshold, -XX:MaxTenuringThreshold and -XX:TargetSurvivorRatio
-XX:+PrintTenuringDistribution 출력을 보여준 튜닝 노브(knobs)는 다양한 플래그들로 인해서 조절될 수 있다. -XX:InitialTenuringThreshold 과 -XX:MaxTenuringThreshold 는 보유기간 임계값의 초기값과 최대값을 지정할 수 있다. 추가로 우리는 young generation GC 끝 시점에서 “To” 타켓 사용률(target utilization)를 지정하기 위해 -XX:TargetSurvivorRatio 사용할 수 있다. 예를들어, -XX:MaxTenuringThreshold=10 -XX:TargetSurvivorRatio=90 조합은 보유기간 임계값에 대해 10 의 상한과 “To” survivor 공간에 대해 90% 의 타켓 사용률을 지정한다.
young generation 동작을 조정하기 위해 이러한 플래그들을 사용하는 서로다른 접근법이 존재하지만 일반적인 가이드라인은 활용할 수 없다. 명확하게 두가지 경우를 제한한다.
- 만약 최종적으로 최대 보유기간 임계값에 도달하기전 보유기간 임계값 많은 객체들은 오래됐고 늙었다걸 보여주고 있다면 이것은 -XX:MaxTenuringThreshold 는 아주 크다는 걸 말해준다.
- -XX:MaxTenuringThreshold 의 값이 1보다 크지만 대부분의 객체가 1보다 큰 세대에 도달하지 못할거라면 우리는 “To” 타켓 사용률(the target utilization)을 찾아봐야 한다. Should the target utilization never be reached, then we know that all young objects get collected by the GC, which is exactly what we want. 그러나, 만약 타켓 사용률이 빠르게 도달한다면, 적어도 1세대 이후에 혹은 조기에 특정 객체들이 old generation 으로 이동되어진다. 이 경우에, 우리는 타켓 사용률과 그들이 크기를 증가시킴으로써 survivor 공간을 개선시도할 수 있다.
-XX:+NeverTenure 과 -XX:+AlwaysTenure
마지막으로, 나는 young generation GC 동작의 두 극단을 테스트하는데 사용할 수 있는 두개의 이국적인 플래그들을 언급하고 싶다. 만약 -XX:+NeverTenure를 지정하면, 객체들은 결코 old generation 으로 옮겨지지 않는다. 이 동작은 old generation 이 필요가 없다고 확신할때 가능하다. 그러나, 그러한 플래그는 분명히 위험하고 예약한 힙 메모리의 절반을 낭비하게 한다. 반대 동작으로 -XX:+AlwaysTenure 는 작동할 수 있다. 첫번째 GC 에서 모든 young 객체들은 즉각 old generation 으로 옮겨 survivor 공간을 사용하지 않게 한다. 이 플래그의 적절한 사용 케이스를 찾기는 어렵다. 테스트 환경에서 어떤 일이 발생할지를 찾기위해서 재미로 할 수 있지만, 나는 이 두 플래그의 사용을 추천하진 않는다.
Conclusion
young generation 에 대한 적절한 구성과 응용 프로그램을 실행하는 것은 중요하며 튜닝을 위해 몇개의 플래그들이 있다. 그러나 old generation 고려없이 young generation 의 튜닝은 성공을 이끌지는 못한다. 힙을 튜닝하거나 GC 세팅을 튜닝할때에 우리는 늘 you generation 과 old generation 의 상호작용을 살펴야 한다.
이 시리즈의 다음 두번에 걸쳐 우리는 HotSpot JVM 에서 제공되는 두개의 기본적인 old generation GC 전략에 대해서 배울 것이다. 우리는 “Throughput Collector” 과 “Concurrent Low Pause Collector” 를 알게될 것이고 그들의 기본적인 원칙, 알고리즘, 튜닝 플래그들을 살펴볼 것이다.