알고리즘 – 분수(Fraction) 문제는 컴퓨터 알고리즘을 시작하는데 좋은 예제입니다. 분수는 어릴적 산수시간에 배운 그게 맞습니다. 1/2, 1/3, 1/4 식 입니다.
분수에는도 사칙연산을 할 수 있습니다. 더하기(add), 빼기(subtract), 곱셈(multiply), 나눗셈(divide) 가 그것입니다. 이를 컴퓨터 프로그램 언어를 이용해서 만들어보는 겁니다.
참고: http://interactivepython.org/runestone/static/pythonds/Introduction/ObjectOrientedProgramminginPythonDefiningClasses.html#a-fraction-class
분수의 정의와 제약사항
분수는 다음과 같이 정의됩니다.
수학에서 분수(分數, fraction)는  이나
이나 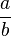 꼴로 표시한다. 이것은
꼴로 표시한다. 이것은  를
를  로 나눈 값, 즉 와 의 비를 뜻하며, 여기서 는 분자, 는 분모라고 한다. 이 때 분모 에
로 나눈 값, 즉 와 의 비를 뜻하며, 여기서 는 분자, 는 분모라고 한다. 이 때 분모 에  이 들어가는
이 들어가는  (는 상수)라는 수는 정의될 수 없으므로 ≠ 이어야 한다.
(는 상수)라는 수는 정의될 수 없으므로 ≠ 이어야 한다.
From 위키페디아
중요한 것이 분모는 0 이여서는 안됩니다. 또 한가지 이 글에서 제약조건을 걸어야 하는데, 분자와 분모 모두 양수로만 이루어진 분수를 다룹니다. 또, 모두 정수여야 합니다. 이를 정리하면 다음과 같습니다.
- 분모는 0 이여서는 안됩니다.
- 분자, 분모는 모두 양의 정수(양수이며 정수)
분수의 덧셈
분수의 덧셈은 먼저 분모를 ‘통분’해야 합니다. 무슨말이냐 하면 덧셈을 하기 위한 두개의 분수들의 분모 크기를 같은 값으로 만드는 것(=분모를 통일하는것)입니다. 예를들어
1/2 + 1/3 이 있다면 분모를 통분하는데 서로서로 분모값을 분자,분모에 곱해주면 됩니다. (1*3)/(2*3) + (1*2)/(3*2) = 3/6 + 2/6 = 5/6
분모가 같아지니까 분자만 그대로 더해주면 됩니다.
분수의 뺄셈
분수의 뺄셈은 분수의 덧셈과 마찬가지로 분모를 통분해주고 분자까리 빼주면 됩니다.
분수의 곳셈
분자는 분자까리, 분모는 분모끼리 곳해주면 끝~
분수의 나눗셈
나누는 분수을 역으로 바꾸고 둘을 곱셈하면 된다.
2/5 나누기 1/3 = 2/5 * 3/1 = 6/5
여기까지가 분수에 관한 수학적 알고리즘입니다.
컴퓨터 알고리즘
컴퓨터 알고리즘은 컴퓨터를 이용해서 문제를 해결하는 방법입니다. 그럴려면 아무래도 프로그래밍을 해야하고 프로그래밍을 위해서는 프로그램 언어를 이용해야 합니다. Python, Java, PHP 등이 여기에 속합니다.
한가지 컴퓨터 알고리즘을 할때에는 선택한 언어의 특성을 이용하는 경우가 있습니다. 예를들어 Python 을 이용할 경우에 내장 메소드를 이용할 수 있는데, 이번 분수 알고리즘에서 이를 사용할 것입니다. 다른 언어로 구현할 경우에는 이러한 Python 의 내장 메소드 기능을 제공하지 않기 때문에 다르게 구현을 해야합니다.
이 말은 결국 컴퓨터 알고리즘을 구현하는데 사용하는 언어에 영향을 어느정도 받는다는 것입니다.
Python 의 특징(python3.4 기준)
Python 은 내장 메소드를 지원합니다. 이는 모든 데이터를 객체로 인식하고 레퍼런스하기 때문에 가능한 것입니다. 단순한 숫자조차도 다양한 메소드를 지원합니다.
|
|
>>> dir(25) ['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes'] |
위에 보시면 숫자에 대한 내장 메소드를 볼수 있습니다. 이 내장 메소드들은 특정한 연산을할때에 자동으로 작동합니다. 예를들어, ‘__add__’ 의 경우는 숫자를 더할때에 자동적으로 호출되어 작동합니다.
|
|
>>> 25+10 35 >>> (25).__add__(10) 35 |
Python 에서 사칙연산에 관한 내장 메소드는 다음과 같습니다.
|
|
>>> (25).__add__(10) # + 35 >>> (25).__sub__(10) # - 15 >>> (25).__mul__(10) # x 250 >>> (25).__truediv__(10) # / 2.5 |
구현하기
Fraction 이라는 클래스를 만들고 내장 함수들을 조작함으로써 완성함으로써 완성됩니다.
먼저 두개의 숫자를 입력받는걸로 분수를 만듭니다.
|
|
#!/usr/bin/python3.4 class Fraction: def __init__(self, top, bottom): self.num = top self.den = bottom |
그리고 덧셈 테스트를 해봅니다.
|
|
>>> obj = Fraction(2,5) >>> obj2 = Fraction(3,4) >>> obj + obj2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'Fraction' and 'Fraction' >>> >>> obj.__add__(obj2) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Fraction' object has no attribute '__add__' |
같은 클래스의 객체를 만들어서 덧셈을 해보면 저렇게 내장 메소드가 없다라고 나옵니다. 그러면 저 내장 메소드를 만들어주면 됩니다.
|
|
#!/usr/bin/python3.4 class Fraction: def __init__(self, top, bottom): self.num = top self.den = bottom def __add__(self, otherfraction): newnum = (self.num*otherfraction.den) + (otherfraction.num*self.den) newden = self.den*otherfraction.den print(newnum, '/', newden) |
위와같이 덧셈 내장 메소드를 정의해주고 다음과 같이 테스트를 합니다.
|
|
>>> from Fraction import * >>> >>> obj = Fraction(2,5) >>> obj2 = Fraction(3,4) >>> >>> obj + obj2 23 / 20 |
잘 되네요. 뺄셈, 곱셈, 나눗셈은 앞에서 말한 방법대로 내장 메소드를 이용해서 구현하면 됩니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
#!/usr/bin/python3.4 class Fraction: def __init__(self, top, bottom): if top < 0 or top == 0: raise RuntimeError("numerator must be above 0") if bottom < 0 or bottom == 0: raise RuntimeError("denominator must be above 0") self.num = top self.den = bottom def __add__(self, otherfraction): newnum = (self.num*otherfraction.den) + (otherfraction.num*self.den) newden = self.den*otherfraction.den print(newnum, '/', newden) def __sub__(self, otherfraction): newnum = (self.num*otherfraction.den) - (otherfraction.num*self.den) newden = self.den*otherfraction.den print(newnum, '/', newden) def __mul__(self, otherfraction): newnum = self.num*otherfraction.num newden = self.den*otherfraction.den print(newnum, '/', newden) def __truediv__(self, otherfraction): newnum = self.num*otherfraction.den newden = self.den*otherfraction.num print(newnum, '/', newden) |
제약조건인 음수와 0에 대한 것을 예외로 처리하였습니다. 다음과 같이 실행 합니다.
|
|
>>> from Fraction import * >>> >>> obj = Fraction(2,5) >>> obj2 = Fraction(3,4) >>> >>> obj + obj2 23 / 20 >>> obj - obj2 -7 / 20 >>> obj * obj2 6 / 20 >>> obj / obj2 8 / 15 |
마이너스(-) 표시가 마음에 안들긴하지만 일단 구현까지만하는 걸로..