몇일 전에 Apache 재단에서 제작해 배포하는 Log4j2 에 대해, 보안 취약점 등급 10등급으로 즉시 취약을 말하면서 보안설정과 패치를 하라는 권고를 했다. 이는 전 세계적인 현상으로 우리나라 뿐만 아니라 미국등에도 매우 심각한 현상임을 인지하고 뉴스에도 나올만큼 큰 뉴스거리가 되었다.
Log4j2 만 문제냐
하지만 이 업계에 10년 넘게 밥벌이를 하는 입장에서 별로 놀랍지도 않고 왜 그렇게 호들갑이냐 하는 생각이 먼저 든다. 모르는 사람이야 뉴스에도 나오고 전문가들이 심각하다고 하는데 ‘호들갑’ 이라고 말하니 내가 뭔가 잘못 말한것처럼 생각이 들겠지만 실상을 알고 나면 그렇지 않다는걸 깨닫게 된다.
먼저, 내가 현재 맡아서 하고 있는 것들을 한번 보자. 대략 다음과 같은 스펙으로 서비스되어지고 있다.
- RedHat Enterprise Linux 7.7
- Spring Boot 1.5
- Java 1.8
- WildFly 13
대충 이렇게 나열해 보면 이게 대체 뭐가 문제냐 하는 생각이 들 것이다.
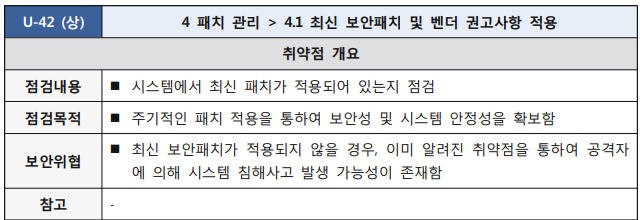
KISA 정보에서 발행한 ‘주요정보통신기반시설 기술적 취약점 분석, 평가 방법 상세가이드’ 라는 것이 있다. 여기에는 특정 요소요소에 대해서 보안 설정을 어떻게 해야하는지를 가이드하고 있는데, 여기에 ‘U-42. 4.1 최신 보안패치 및 벤더 권고사항 적용’ 이란게 있다.
요약을 하자면 항상 최신의 패치 적용을 유지하라는 것이다.
그런데, RedHat Enterprise Linux 7.x 에 최신 버전은 7.9 이다. 더 최신은 RedHat Enterprise Linux 8.5 다. 시스템에 설치된 어떤 프로그램이 보안 취약점을 들어내고 있는지에 대해서 알지도 못하고 어짜피 네트워크가 단절되어 있어서 외부에 침입이 어렵다는 변명으로 운영체제(OS)에 대한 최신 패치 적용을 전혀 하지 않는다.
최신의 RHEL 을 사용하지 않는건 일단 내려놓더라도 쓰지도 않는 각종 프로그램들이 다 설치되어 있다. 대표적인게 gcc 컴파일러이다. 어디 gcc 컴파일러 뿐이랴.. g++ 도 있고 automake, autoconf, bison 등 C 소스코드를 컴파일 할 수 있도록 아주 다 깔려 있다.
크랙커가 가장 좋아라하는 시스템이 뚫어서 들어가보니 각종 컴파일러가 설치되어 있는 시스템이다. 컴파일러만 설치되어 있으면 마음대로 시스템을 가지고 놀수 있다. 그래서 될 수 있으면 컴파일러는 설치를 하지 말아야 한다. 아니 더 정확하게는 사용하지 않거나 불필요한 프로그램들과 명령어는 아예 설치를 하지 말아야 한다.
더 놀라운 것은 Java 시스템인데도 각종 gcc, g++ 컴파일러가 설치되어 있고 각종 라이브러리까지 아주 풍부하다는 것이다. 이에 대해서 이러면 안된다고 하면, 각종 보안 프로그램들이 철벽으로 작동하고 있고 ISMS 심사를 받았으니 됐다고 말한다.
Spring Boot 1.5 – 지원 끝
지원이 끝난 프레임워크다. 일단 지원이 끝났다면 될수 있는대로 빠르게 업데이트를 해야 한다. 하지만, 작동하는데 아무런 문제가 없으니까 계속 사용한다. 뭔가 문제가 생기면 그 라이브러리만 업데이트 하는 식이다.
Spring boot 1.5 전체를 패키지는 방대한데, 그중에서 자주 사용하는 일부가 문제가 생겼다는 뉴스가 나오면 그것만 바꾸는 식이다.
이렇다보니 Spring boot 2.x 에 대한 기술 습득은 꿈도 못꾼다. Reactive 가 뭐고 그래서 그게 뭐가 좋은지도 모르고 그것을 하면 뭐가 이득이 된다는 것은 둘째고 기술지원도 끝난 프레임워크를 그대로 고수하면서 DB 구조를 파악하고 데이터를 넣다 뺏다 하는 CRUD 프로그래밍으로 화면에 원하는 것을 이루게 되면 그것이 프로그래밍이 된 것이라는 사고방식에 젖어 있다.
고민따위는 안중에도 없고, 구글에서 검색해서 읽어본 기사에 뭘 좀 안다고 지식자랑하기에만 바쁘고 정작 책상에 앉아서 하는 일이라곤 지식자랑과는 한참 뒤처진 기술들을 다루고 있을 뿐이다.
지원이 끝났다는 것은 더 이상 보안관련 업데이트를 해주지 않는다는 것을 뜻한다. 물론 전 세계적으로 문제가 될 경우에 End Of Life 가 된 경우라도 업데이트를 제공해 주긴 한다. 하지만 지원이 끝난 것들은 더 이상 보안에 대해서 신경을 놔버리는 경우고 거들떠도 안보다는 사실을 알아야 한다.
아무도 신경을 안쓰는 거들떠보지도 않는 프레임워크로 일을 하는 것이 뭐 그리 대단한지, 단가 900 은 받아야겠다고 하는데 괜히 프리 경력이 정규직 경력을 인정받지 못하는게 아니다.
이렇게 글을 적어놓으면
프로젝트 오퍼를 낸 조직이 가이드를 내놓고 어떻게 하라고 해야지 그걸 왜 프리보고 뭐라 하냐?
이렇게 말할게 뻔하다. 그러니까 정규직 경력이 안되는 거다. 정규직에서는 적극적인 사람을 원하지 그렇게 수동적으로 뭐 가이드 안주면 못하겠다는 식의 사고를 가진 사람을 뽑으려 하지 않는다. 그것도 적어도 경력이 10년 이상이라면 이렇게 해서는 안된다, 이런 것쯤은 좀 바꿔야 한다는 정도도 있어야 하고 적극적으로 문제에 대해서 문제가 있으며 바꿔야 한다는 것을 적어도 어필 정도는 해줘야 하는데, 그런게 안되잖아..
더 큰 문제는 대충한다는데 있다. Spring Framework 3.x 처럼 오래된 것이긴 하지만 나름대로 프로그래밍 방법들이 존재한다. 과거에는 쓸만했던 것이여서 자료를 찾아보면 그때당시에 자료들도 상당하다. 그러면 Spring Framework 3.x 에 대한 그 때 당시에 쓸만했던 것을 지금에 쓰고 있느냐… 그냥 다 대충한다. 어짜피 딴데가면 안쓸거… 구형인데 뭐… 이거 열심해서 뭐하냐…. 아무도 열심히 안한다.
어짜피 구형이라 열심히 안하고 그렇다고 뭐 바꾸자는 제안조차 못하고… 그냥 돌아가게만 만들자식이란게 문제다.
Wildfly 13 – End Of Life
Wildfly 는 예전에 Jboss AS 라는 오픈소스 엔터프라이즈 자바 서버였다. 그러던 것이 Redhat 에서 프로젝트를 인수(?) 하고 자사의 상용 엔터프라이즈 자바 서버를 Jboss EAP 라는 이름을 붙이자 네이밍에 차이를 두기 위해서 Wildfly 로 이름을 바꾼다.
Wildfly 는 이름을 바꾼것만이 아니라 릴리즈 주기를 바꾸게 되는데, 분기마다 메이저 업데이트를 하는 정책으로 바꾼 것이다. (분기마다 인지 1년마다 인지… 정확하지는 않음. 몇달 주기로 메이저 업데이트를 하겠다는 정책임) 이러한 정책은 Wildfly 의 Long Term Support 버전이 없다는 것을 말한다.
업데이트를 못 쫓아가는건 당연하고 무엇보다 JEE 스펙도 버전이 올라감에 따라 달라지다 보니 Servlet 엔진을 필요로하는 경에 버전 호환성이 맞지 않는 경우가 생긴다. 그것조차도 그렇다 치더라도 Wildfly 13 도 지원이 끝나기는 마찬가지다.
이렇게 주기적인 메이저 업데이트를 하는 자바 서버에 경우에 주기적으로 업데이트를 할 수 없는 경우에는 선택을 하지 말았어야 했다. RHEL 도 한번 설치하면 업데이트를 안하고 버티는 경우가 부지기수인데, 주기적인 업데이트를 고려해서 이것을 선택햇을리는 만무하다.
금융권은 더 심각
현재 내가 하고 있는 프로젝트의 경우에 한정해서 말을 하다보면, “그건 니가 있는 곳이 ㅈ같은 경우지… 똥 밟은 너를 탓해라” 하는 인간들이 대다수다.
그렇다면 과거, 그것도 긴 과거가 아닌 올해 있었던 금융권 프로젝트를 예를들어보자.
- RedHat Enterprise Linux 7.7
- gcc, g++ 컴파이러, automake, autoconf
- WebLogic 12.1.x
- Spring Framework 3.x
이런 환경에서 마이데이터니 뭐니,, 모바일이니 뭐니 서비스하고 앉아 있는게 현실이다.
더 웃긴건, WebLogic 서버를 사용하는데 환경은 AWS 클라우드에 올렸다는데 있다. 이게 뭐가 문제가 되느냐 하겠지만 WebLogic 는 Admin 서버와 Managed 서버로 나뉘며 Admin 서버가 반드시 있어야 하고 Managed 서버가 Admin 서버에 등록이 되어 있어야 한다.
이렇게 되면 AWS 클라우드에서 반드시 사용해야만 하는 AutoScaling 을 이용할 수가 없다. 물론 아예 이용할 수 없는 것은 아니지만, 별도의 노력이 조금 더 들어간다. 하지만, 그 별도의 노력조차도 안해서 그런지 AutoScaling 은 아예 접었고 닭 한마리 이벤트를 날리면 접속자가 폭주해 장애가 나는 곳이 금융 시스템이다.
KISA 도 결국 문제
이래저래 문제 해결을 위해서 노력한다고 하지만 한개는 있다. 그중에 다음과 같은 말들을 많이 한다. 적어도 금융권에서는..
Redhat Enterprise Linux 8.x 는 아직 보안 인증이 안됐다.
누가 어떻게 RHEL 8.x 에 대해서 보안인증을 해주나? KISA 가? KISA 가 발행하는 취약점 가이드에 Linux 에 대해서 RHEL 7 기준으로 설명되어 있어서 RHEL 8.x 는 아직 인증 없는 거다?
KISA 가 발행하는 취약점 가이드에는 위와같이 유의사항이 나와 있다. 하지만 현장에 있다보면 ‘인증이 아직 안됐다’ 라는 말을 많이 듣는다. 공공금융 프로젝트에서 인증을 안해준건지 뭔지 모르겠지만, KISA 라는 ISMS 주관사에서 저렇게 하고 있음에도 불구하고 다른 권위도 없고 보안에 관련해 국가적 위임도 받지 않는 곳에서 ‘인증’ 이란걸 하고 있다면 KISA 가 적극적으로 나서서 못하게 해야 한다.
더군다나 KISA 의 경우에 보안 취약점 가이드에는 절대로 하지 말아야 하는 항목들은 없다. 예를들어 ‘gcc 컴파일러 설치 금지’ 와 같은 것들도 없고 End of Life 된 운영체제나 프레임워크에 대한 금지 항목도 없다. ISMS 라는게 결국에는 가이드에 맞춰서 그걸 했냐하는 정도에 그치다보니 ‘그것만으로 됐다’ 하는 것으로 끝이다.
국가기관이 저렇게 나약하게, ‘절대적 기준 아니다’, ‘다양한 점검 방업을 사용하여 취약점 분석평가를 수행’ 등.. 말이 좋아서 저런 표현이지 그냥 대놓고 “니들이 알아서 잘 해봐라” 식과 뭐가 다르냐?
Log4j2 보안 취약점 패치
현재 프로젝트에서 log4j 보안 취약점 패치를 위해서 살펴보니 log4j 1.x 버전이였다. 지금의 log4j2 의 보안취약점은 JNDI 관련되어 있는데, log4j 1.x 에는 JNDI 기능 자체가 없다. 따라서 본 취약점에는 아무런 문제가 없다.
이런식의 결론에 도달하게 되어서 결국에는 아무런 조치도 하지 않았다. log4j 1.x 는 더 이상 유지보수가 안되는 버전이다. 하지만 이번에 터진 취약점과는 관계가 없기 때문에 그런대로 넘어가는 거다.
라고 윗분들의 결정했다. 이게 대한민국의 현주소다.
그래서 log4j 를 그냥 놔둘수도 없고 해서 logback 으로 바꿔 놓을려고 생각중이다. 테스트를 해보니 잘 될거 같다. 보고 따위는 안한다.. 그냥 바꿔놓는 거지.. 그냥 바꿔놔도 모른다. 아무도.. ㅋㅋ