Table of Contents
AWS Athena 는 로그 분석 서비스로 Hive 와 같다. 가장 많이 쓰이는 부분이 VPC Flow Log 를 분석하는데에 Athena 를 이용하는 방법이다. 이 글에서는 어떻게 VPC Flow Log 를 Athena 를 통해서 분석하는 알아 본다.
VPC Flow Log 설정
VPC Flow Log 설정은 간단하다. VPC 에서 Flow logs 탭에서 설정하면 그만인데, 다음과 같은 파라메터를 필요로 한다.
- Destination Type: S3
- Destination Name: S3 로 지정했을 시에 S3 Bucket 이름.
- Log record format: AWS default format
- Log file format: Text (default)
- Partition logs by time: Every 24 hours (default)
여기서 중요한 것은 밑에서 3가지 정도다. Log record format 을 바꿀 경우에 Athena 테이블 생성시에 맞춰야 한다. Partition logs by time 을 24 시간으로 하면 S3 버킷 안에서 2022/08/29 형식으로 폴더가 생성되면서 VPC 로그가 전송 된다. 하루에 한번 폴더를 생성하면서 로그가 쌓인다는 뜻이다. 만일 Every 1 hours (60 minutes) 으로 할 경우에 2022/08/29/09 폴더가 생성되면서 로그가 쌓인다. 이 폴더의 구조는 나중에 Athena 에서 파티션 프포젝션(Partition Projection) 을 설정할때에 참고하게 된다.
또, S3 버킷으로 전송할 경우에 S3 의 암호화를 SSE_S3 로 할 것을 권장한다. CMK 로 할 경우에 로그가 쌓이지 않을 가능성이 있다. 또, 향후에 권한지정에서 CMK 권한을 함께 줘야하는 복잡함이 있을 수 있다.
S3 버킷 확인
필자의 VPC Log 설정으로 인해서 S3 에는 다음과 같은 형태로 S3 에 로그가 쌓이고 있다.

버킷 이름만 지정해주면 그 안에 AWSLogs/계정ID/vpclfowlogs/ap-northeast-2/ 가 자동으로 생성되며 그 안으로 year/month/day 순으로 생성된다.
앞에서 VPC Flow Logs 설정할때에 Partition logs by time 에서 Every 24 hours (default) 로 지정했기 때문에 날짜별로 생성된다.
Athena 작업
작업그룹(Workgroups) 생성
먼저 Athena 에서 필요한 것이 작업그룹(Workgroups) 이다. 기본적으로 Primary 가 기본 생성되어 있지만 하나 생성한다. 생성할때에 필요한 것은 다음과 같다.
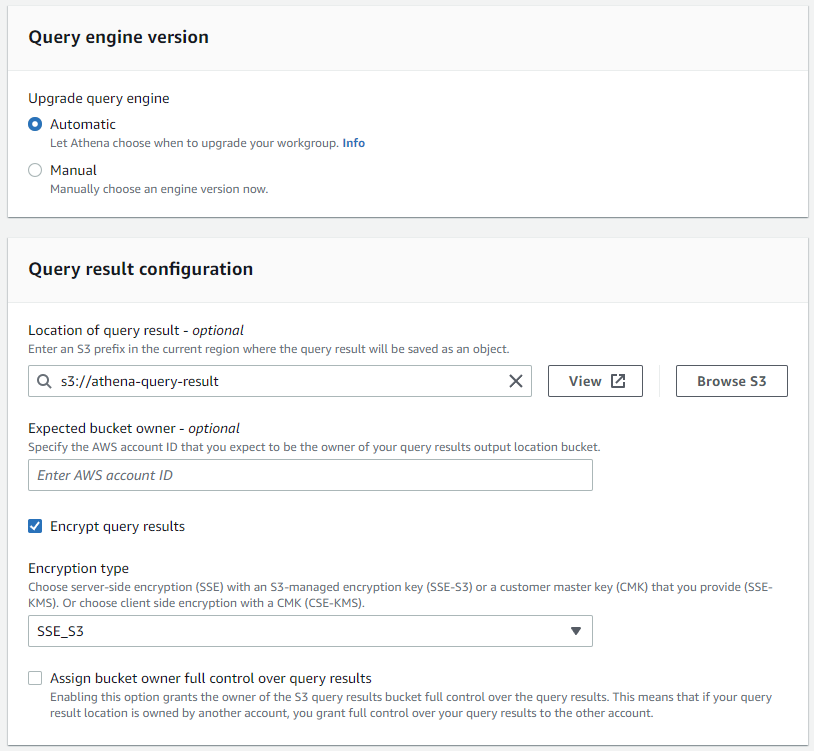
쿼리 결과를 받을 S3 를 지정해야 한다. 만일 암호화가 필요하다면 SSE_S3 를 권장한다. CMK 도 가능하지만 Role 설정을 잘 해줘야 한다.
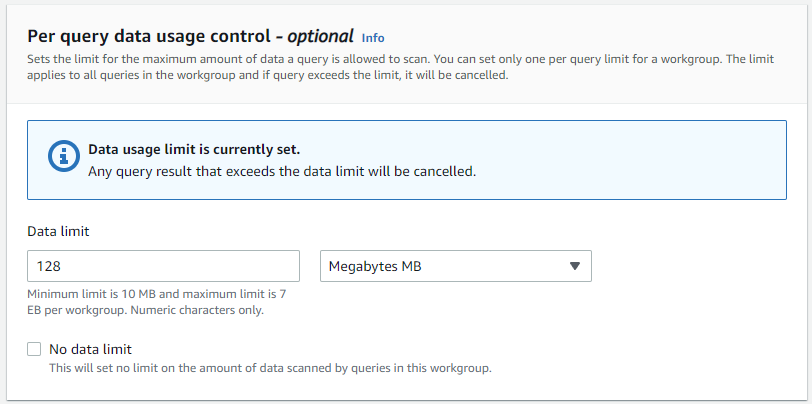
데이터 사용량을 적절하게 조절해 주길 권장한다. 덮어놓고 좋다고 No limit 로 하는 순간 돈이 술술 나갈 것이다. 이 데이터 사용량은 얼마든지 설정을 변경할 수 있다.
Database 생성
Query Editor 로 이동해 화면 오른쪽 상단에서 앞에서 생성한 작업그룹(Workgroup) 으로 변경해 준다.
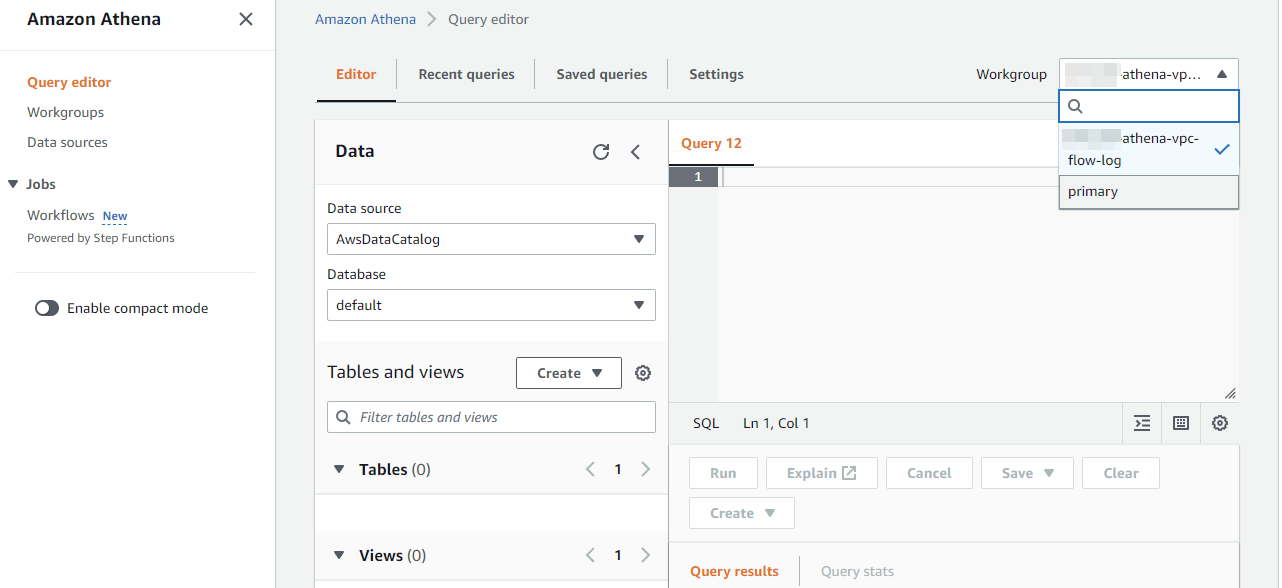
그러면 Workgroup 이 변경 된다. 이제 다음과 같이 Database 를 생성해 준다.
CREATE DATABASE vpcflowlogs
위 쿼리문은 화면안에 쿼리입력창에 입력하고 ‘Run’ 을 클릭해주면 된다.
이렇게 하면 데이터베이스가 생성이 된다. 그리고 왼쪽에 Database 부분에서 새로 생성한 데이터베이스를 선택해 준다.
위와같은 상태가 된다면 이제 테이블을 생성해야 한다.
Table 생성
이제 Table 을 생성해야 한다. 테이블을 생성할때에 중요한 것이 VPC Flow Log 의 S3 저장소와 데이터 컬럼들이다. 다음과 같다.
CREATE EXTERNAL TABLE IF NOT EXISTSvpc_flow_logs(versionint,account_idstring,interface_idstring,srcaddrstring,dstaddrstring,srcportint,dstportint,protocolbigint,packetsbigint,bytesbigint,startbigint,endbigint,actionstring,log_statusstring ) PARTITIONED BY (datedate) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LOCATION 's3://flow-log-buckets/AWSLogs/1111122222233333/vpcflowlogs/ap-northeast-2/' TBLPROPERTIES("skip.header.line.count"="1")
테이블을 생성할때에 컬럼을 지정해 줘야 하는데, VPC Flow Log 설정할때에 record format 을 AWS Default Format 을 지정했는데, 그 포맷은 위와 같다. 이 컬럼들은 S3 에 저장된 파일을 열었을 때에 맨 처음 나오는 행에 컬럼헤더 값들이다. 정확히는 ‘_’ 가 ‘-‘ 로 보면 정확하다. Athena 테이블은 ‘-‘ 를 ‘_’ 로 변환된다.
중요한 것은 Partitioned BY 부분에 date 부분이다. 테이블을 파티셔닝을 하기 위한 기준이 되는 컬럼을 추가하는 것이다. 이 파티션 컬럼은 S3 에 저장되는 VPC Flow Log 에는 없는데 파티셔닝 테이블을 생성할때에 이름처럼 생성된다.
위 쿼리문을 실행해 테이블을 생성한다.
파티션 생성
만일 파티션이 없다면 쿼리 시간이 길어진다. VPC Flow Log 의 경우 날짜로별로(yyyy/MM/dd) 쌓이는 것에 창안해 파티션을 날짜별로 생성하도록 할 것이다. 다음과 같이 파티션을 생성해준다.
ALTER TABLE vpc_flow_logs
ADD PARTITION (date='2022-08-29')
LOCATION 's3://flow-log-buckets/AWSLogs/1111122222233333/vpcflowlogs/ap-northeast-2/2022/08/29';
이렇게 하면 2022/08/29 에 해당하는 버킷에 내용이 파티션으로 입력 된다.
파티션을 이용하면 데이터 조회시에 그 범위가 줄어든다. 정확하게는 데이터 스캔(Data Scan) 범위를 줄일 수 있어서 쿼리 속도를 높여줄 뿐만 아니라 스캔 범위가 줄어들기 때문에 데이터를 긁어오는 양도 줄게되어서 비용을 아낄 수 있다.
앞에서 만든 테이블의 경우 date 컬럼은 date 테이터 타입임으로 다음과 같은 쿼리가 가능하다.
SELECT * FROM vpc_flow_logs WHERE 'date' > DATE('2022-08-28') - interval 1 day and 'date' < DATE('2022-08-28') ORDER BY start DESC LIMIT 10
date 타입이기 때문에 문자열을 date 타입으로 해줘야 한다.
파티션 생성 문제
파티션을 생성하면 문제가 하나 있다. 날짜별로 하나하나 다 생성해 줘야 한다. 시간은 흐르고 날짜는 변경될 것이다. 내일이 되면 다른 날짜로 S3 에 폴더가 만들어지고 거기에 데이터가 쌓일 것이다. 그러면 Athena 에서 그 날짜에 맞는 S3 저장소의 파티션을 생성해줘야 한다.
매일매일 하루에 한번 이것을 해야 한다고 생각하면 힘들다.
이것을 자동으로 하는 방법은 존재한다. Lambda 를 이용하는 것이다.
Lambda 작성하기
Lambda 실행을 위한 Role 생성
Lambda 를 작성해 자동으로 매일매일 하루에 한번 파티션을 생성하도록 해보자. Lambda 를 실행하기 위해서는 먼저 Lambda 실행을 위한 Role 이 필요하다.
## Role Name: ServiceRoleForVPCFlowLogsAthenaIntegrated
# Trust Relationships
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
# Inline Policy: VPCFlowLogsAthenaIntegrationLambdaExecutorPolicy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucketMultipartUploads",
"s3:PutBucketPublicAccessBlock",
"s3:AbortMultipartUpload",
"s3:CreateBucket",
"s3:GetBucketLocation",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::athena-query-result/*",
"arn:aws:s3:::athena-query-result"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::flow-log-buckets/*",
"arn:aws:s3:::flow-log-buckets"
]
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults"
],
"Resource": [
"arn:aws:athena:ap-northeast-2:111111222222333333:workgroup/*"
]
},
{
"Sid": "VisualEditor3",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"glue:GetPartition",
"s3:ListAllMyBuckets",
"s3:ListBucket",
"glue:CreatePartition",
"s3:GetBucketLocation",
"logs:CreateLogGroup",
"logs:PutLogEvents",
"glue:UpdatePartition",
"glue:GetTable",
"glue:GetDatabase",
"glue:BatchCreatePartition"
],
"Resource": "*"
}
]
}
Lambda 실행을 위한 Role 을 위와같이 생성해 준다.
Lambda 생성
Lambda 는 여러가지 언어로 작성될 수 있는데, 여기서는 Python 을 이용했다.
# Lambda Name: aws-athena-vpc-flow-log-Partitioner
import boto3
import datetime
import logging
import time
import re
# setup simple logging for INFO
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# setup variables
athena_workgroup = "athena-vpc-flow-log"
catalog_database = "vpcflowlogs"
flowlog_bucket="flow-log-buckets"
account_id = "111112222233333"
flowlog_table = "vpc_flow_logs"
# define the connection
athena = boto3.client('athena','ap-northeast-2')
def lambda_handler(event, context):
today = datetime.datetime.utcnow()
#today += datetime.timedelta(hours=10) # Convert KST
logger.info('Today: {}'.format(today))
year = today.strftime("%Y")
month = today.strftime("%m")
day = today.strftime("%d")
############################################################################
# VPC Flow Log Catalog 테이블 파티션 갱신
############################################################################
query = """
ALTER TABLE {}
ADD PARTITION (date='{}-{}-{}')
LOCATION 's3://{}/AWSLogs/{}/vpcflowlogs/ap-northeast-2/{}/{}/{}'
""".format(flowlog_table, year, month, day, flowlog_bucket, account_id, year, month, day)
logger.info("Query: {}".format(query))
response = athena.start_query_execution( QueryString=query,
QueryExecutionContext={
'Catalog': 'AwsDataCatalog',
'Database': catalog_database
},
WorkGroup=athena_workgroup,
ResultConfiguration={
'OutputLocation': 's3://aws-athena-query-result/',
'EncryptionConfiguration': {
'EncryptionOption': 'SSE_S3'
}
}
)
query_execution_id = response['QueryExecutionId']
logger.info('CodeIssue PRD Execution ID: {}'.format(query_execution_id))
time.sleep(10)
state = 'RUNNING'
max_execution = 5
while (max_execution > 0 and state in ['RUNNING', 'QUEUED']):
max_execution = max_execution -1
results = athena.get_query_execution(QueryExecutionId = query_execution_id)
if 'QueryExecution' in results and \
'Status' in results['QueryExecution'] and \
'State' in results['QueryExecution']['Status']:
state = results['QueryExecution']['Status']['State']
if state == 'FAILED':
logger.info("Query Result Failed: {}".format(results))
elif state == 'SUCCEEDED':
s3_path = results['QueryExecution']['ResultConfiguration']['OutputLocation']
filename = re.findall('.*\/(.*)', s3_path)[0]
logger.info("Query Result S3: {}".format(filename))
break
time.sleep(1)
Lambda 를 실행하는 Roles 는 앞에서 작성한 Roles 를 지정해 준다.
EventBridge Rule 생성
EventBridge 에서 Rule 를 생성해 매일 자정 0시 0분에 람다를 실행하도록 설정해 준다.
KST 를 위한 Athena 테이블 View 생성
Athena 에 vpc_flow_logs 테이블에 start, end 컬럼은 unixtime 이지만 UTC 기반이다. 이것을 KST 기반으로 보기 위해서는 연산이 필요한데, 그것을 아예 View 만들어 놓으면 좋다.
CREATE VIEW vpc_flow_logs_kst AS
SELECT
"version"
, "account_id"
, "interface_id"
, "srcaddr"
, "dstaddr"
, "srcport"
, "dstport"
, "protocol"
, "packets"
, "bytes"
, ("from_unixtime"("start") + INTERVAL '9' HOUR) "start"
, ("from_unixtime"("end") + INTERVAL '9' HOUR) "end"
, "action"
, "log_status"
, "date"
FROM
vpc_flow_logs
이제는 vpc_flow_logs_kst 뷰(view) 에 질의를 하면 start, end 컬럼의 데이터가 KST 시간으로 표신된다.
결론
지금까지 VPC Flow Log 생성에서부터 Athena 를 이용하는 방법, 더 나가 자동으로 파티션을 생성하도록 Lambda 까지 작성해봤다.
하지만, Lambda 작성도 필요없는 방법이 있다. 파티션 프로젝션(Partition Projection) 이라고 불리는 방법인데, 이것은 처음 테이블을 생성할때에 S3 의 날짜 폴더 구조를 기반으로 자동으로 파티션을 인식시키는 방법이다. 이렇게 하면 Lambda 를 이용해 파티션을 수동으로 생성해줄 필요가 없게된다.