Table of Contents
Oracle, MariadB, MySQL 등과 같은 관계형 데이터베이스를 다루다보면 시스템 튜닝에 대해서 많이 접하게 된다. 특히나 리눅스 시스템에서 이들 데이터베이스 시스템이 제대로 작동하기 위한 운영체제 차원에서 필요한 작업을 많이 하게 된다.
이러한 운영체제 차원에서 작업은 여러가지가 있어서 알아야 하는 내용도 많고 세팅해야 하는 것도 많다. 대부분 인터넷이나 가이드 북을 이용해 어찌어찌 설정을 한다고 하지만 많은 사람들이 그것이 왜 필요한지 깊게 이해하는 사람들은 드물다.
그래서 아주 간단하게 데이터베이스 시스템을 다루는데 있어 리눅스 운영체제에서 필요로 하는 작업에 필요한 배경지식에 대해서 다루어 보고자 한다.
가상 메모리 관리(Virtual Memory Management)
모든 운영체제는 가상 메모리 관리 기법을 사용한다. 가상이라는 말에서 보이듯이 메모리를 가상화 한다는 이야기인데, 정확하게 말하면 실제로 물리적 메모리의 양이 정해져 있는데도 불구하고 그보다 많은 메모리를 필요로하는 애플리케이션을 구동할 수 있게 해주는 기법이다.
가상 메모리 관리 기법이 존재하기 전에는 실제 물리적 메모리 보다 많은 애플리케이션을 실행할 수 없었다. 더군다나 현대의 운영체제는 멀티 태스킹(Multi Tasking) 으로 운영되기 때문에 이들 애플리케이션 모두가 사용하는 메모리 양을 계산해보면 실제 물리적 메모리보다 많다. 그런데도 신기하게도 아무런 문제 없이 작동되는데 가상 메모리 기법 때문이다.
가상 메모리 관리에서 운영체제는 실제 주소가 아닌 가상 메모리 주소에 접근하게 된다. 하지만 실제 데이터는 물리적 메모리에 존재하기 때문에 가상 메모리 주소를 물리적 메모리로 변환해줘야 할 필요가 있다. 이렇게 가상 메모리 주소를 물리적 메모리 주소로 변환해주는 것이 MMU(Memory Management Unit) 이다.
이 MMU 는 물리적으로 CPU 내부에 존재한다. 현대의 거의 대부분의 CPU 에는 이런 MMU 가 다 있다.
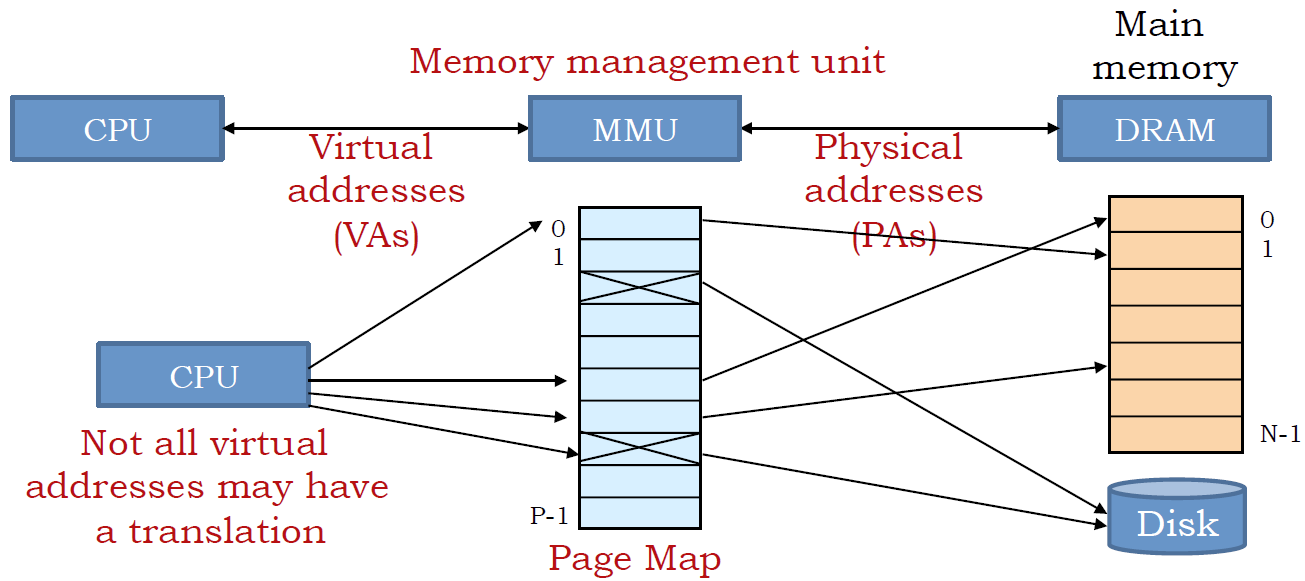
MMU 는 가상 메모리 주소를 실제 물리적 주소로 변환해주는 것인데, 내부적으로 가상 메모리 주소와 물리적 주소를 매핑 시켜놓는 테이블이 존재한다.
일종의 매핑 테이블(Mapping Table) 인데 매핑 테이블은 가상 메모리 주소와 물리 메모리를 페이지(Page) 단위로 관리하도록 되어 있다. 쉽게 말하면 가상 메모리 주소 공간을 특정 크기 단위로 쪼갠 페이지, 실제 물리 메모리 주소를 특정 크기 단위로 쪼갠 페이지를 서로 매핑 시켜 논 것이다.
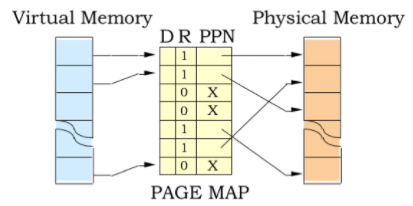
위 그림을 보면 가상 메모리, 물리 메모리가 양 옆에 있고 중간에 주소변환을 위한 페이지 맵(PAGE MAP) 혹은 테이블 이 존재한다.
MMU 느린 속도
MMU 내에 페이지 테이블이 존재는 가상 메모리를 물리 메모리로 빠르게 변환 시켜준다. MMU가 CPU 내부, 반도체 내부에 유닛으로 존재하다보니 소프트웨어에 비하면 속도가 매우 빠르다.
그런데, CPU 에서 가상 메모리에 접근할때 마다 페이지 테이블 전체를 스캔해야 한다. 그래야만 실제 데이터를 가지고 올 수 있을 테니까. 아무리 반도체 칩으로 구현되어 있어도 이렇게 데이터 접근시마다 페이지 테이블 전체를 스캔하면 아무해도 속도가 나질 않는다.
만일 페이지 테이블이 엄청나게 크다면 이 또한 속도에 영향을 준다.
느린 속도… 캐쉬가 답이다.
그래서 MMU 에 페이지 테이블 검색 속도를 높이기 위해서 중간에 캐쉬를 놓게 되었는데 이것이 바로 TLB(Translation Lookaside Buffer) 이다.
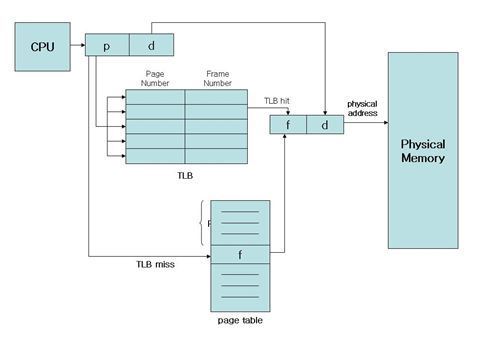
위 그림은 가상 메모리 접근에 MMU 내부의 페이지 테이블과 TLB 가 작동하는지를 보여주는 그림이다. 간단하게 설명하면 CPU 는 무조건 TLB 를 먼저 찾는다. 캐쉬이다 보니까 필요로하는 데이터가 TLB 에 접근하면 찾을 수 있는지 검색을 하는 것이다. 만일 있다면 TLB 를 이용해서 물리 메모리에 접근하게 된다.
하지만 TLB 에 없다면 그때는 페이지 테이블을 전부 스캔하게 된다. 이렇게 페이지 테이블 스캔은 전체적으로 메모리 접근 속도에 영향을 주게 되고 전체적인 운영체제 성능에 영향을 미치게 된다.
4kb 크기의 페이지 문제
리눅스 운영체제에서 한 페이지 단위는 4kb 크기다. 만일 128GB 의 물리 메모리를 장착할 경우에 32M(약 3천 2백만) 개 정도의 페이지가 존재하게 된다. 이 많은 페이지를 페이지 테이블에 쑤셔 넣고 전체 스캔을 하게 되면 아무리 빠른 CPU라도 느릴 수밖에 없게 된다.
또한, 많은 양의 페이지는 TLB 에도 영향을 주게 된다. 너무나 많은 페이지가 존재 하다보니 캐쉬를 했던 페이지의 hit 율이 떨어져 자꾸 페이지 테이블 스캔을 하게 되는 것이다.
페이지 테이블이 페이지가 적고 캐쉬해야하는 양이 많으면 페이지 테이블를 스캔해야하는 일이 줄어든다.
HugePage 는 TLB 의 Hit 를 높여준다
Huge Page 는 기본 페이지 크기 4kb 를 크게 하는 기법이다. 이 기법을 사용하면 페이지 갯수가 줄어든다.
그런데, 많은 사람들이 페이지 크기를 늘리게 될 경우에 그 페이지가 가지는 데이터의 양을 한꺼번에 접근할 수 있어서 효율이 높아진다고 생각하는 경우가 많다. 물론 그런 영향이 없지는 않지만 Huge Page 를 하는 이유는 TLB 의 Hit 를 높여주는, 반대로 TLB 의 Miss 를 낮춰주는데 있다.
TLB 의 Hit 를 높여주면, 캐쉬 사용을 높여주면 데이터 접근이 빨라진다. 이것은 전체적인 운영체제의 메모리 성능을 높여주는 효과를 보여주게 된다. TLB Hit 를 위해서 간단한 방법이 바로 페이지 크기를 늘려주는 것이다. 4kb 마다 한 페이지가 아닌 2MB 마다 한 페이지라면 페이지 테이블 크기도 줄어들고 TLB 에 캐쉬된 페이지의 Hit 가 높아지게 된다.
Huge Page 사용 전략
HugePage 를 무턱대고 설정해서는 안된다. 일종의 전략이 반드시 필요하다.
- OS 에서 지원해 줘야 한다.
- 애플리케이션에서 지원해 줘야 한다.
- 공유 메모리 설정과 연계되어 있다.
HugePage 를 사용하면 무조건 OS 상에 성능이 개선되는게 아니다. OS 에서는 당연히 사용을 하겠지만 애플리케이션에서도 HugePage 사용이 가능해야 한다.
HugePage 가 사용 가능한 애플리케이션으로 데이터베이스 시스템이 있다. PHP 와 같은 경우에도 사용이 가능하다고 한다.
무엇보다 중요한 것은 HugePage 설정은 단일 애플리케이션 시스템에 적합하다. Oracle 데이터베이스 하나만 작동하는 시스템이나 MySQL 하나만 작동하는 시스템등 여러 애플리케이션이 아니라 단일 애플리케이션만 구동하는 환경이라야 한다.
리눅스에서 HugePage 설정
MariaDB 를 위해 설정을 진행 해보자. 환경은 다음과 같다.
- CentOS 8 64bit
- RAM 4G
- MariaDB 10.5.8
가장 먼저 해야할 것은 Transparent Huge Pages (THP) 설정을 never 로 바꾸는 것이다. THP 는 HugePage 를 자동으로 맞춰주는 기능인데, 성능 하락을 가져오기도 한다.
커널 파라메터를 수정하는 방법도 있지만 grub 에 부팅 옵션을 추가하는 것이 가장 간단하다.
]# vim /etc/default/grub - GRUB_CMDLINE_LINUX="crashkernel=auto resume=UUID=746f00f3-6aaf-4141-b166-03241f2e0d7f rhgb quiet" + GRUB_CMDLINE_LINUX="crashkernel=auto resume=UUID=746f00f3-6aaf-4141-b166-03241f2e0d7f rhgb quiet transparent_hugepage=never" ]# grub2-mkconfig -o /boot/grub2/grub.cfg ]# grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg # EFI Bios 경우
위와같이 한 다음 재부팅을 한번 해주면 적용 된다.
현재 상태를 살펴보자. /proc/meminfo 를 보면 알 수 있다.
]$ grep -i '^Huge' /proc/meminfo HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 0 kB
내용을 보면 아직 HugPage 를 사용하고 있지 않다고 나온다. 여기서 이제 계산이 필요하다. 얼마만큼 사용할 것인가, 누가 사용할 것인가 결정해야 하는 것이다.
MariaDB 를 사용할 것인데, MariaDB 를 사용하는데 있어서 InnoDB 를 사용할 것이다. InnoDB 는 Innodb pool 이 주로 메모리를 사용할 것인데, MariaDB 의 경우 물리 메모리에 약 70% 를 Inndb Pool 로 할달할 것을 권고 하고 있다. 나머지 10%는 MariaDB 자체 운영을 위해서 필요 하다. 전체 물리메모리에 약 80%에 해당한다.
df -k 했을때 나오는 전체 메모리 양이 3825740 kb(약 3.8GB) 인데, 이것에 80% 이면 3060592 kb 이다. 이것을 다시 2048 kb (한 페이지 크기) 로 나누면 1494.4296875 인데, 대략 1500 정도로 해두면 될 듯 하다.
이것을 이제 커널 파라메터로 넘겨 준다. sysctl.d 디렉토리에 파일을 만들어 별도로 관리해준다.
]# vim /etc/sysctl.d/10-memory.conf vm.nr_hugepages = 1500 # vm.hugetlb_shm_group=27 ]# sysctl --load /etc/sysctl.d/10-memory.conf vm.nr_hugepages = 1500
vm.hugetlb_shm_group 은 hugetlb 를 사용할 리눅스 시스템 그룹을 지정한 것이다.
MariaDB 에서 설정하기
시스템에서 HugePage 사용을 설정했다고 MariaDB 가 알아서 사용하지 않는다. my.cnf 서버 설정 파일에서 사용하도록 지정해 줘야 한다.
[mariadbd] large-pages
본문에 MMU가 page table 전체를 찾는다고 했는데, 매번 전체를 찾아보지 않습니다.
page table이 작아지면 조회할 전체 크기가 줄어들기때문에 특정 방식에서 효율적인 것은 맞으나 항상 빠르지 않아요
page table은 일단 process마다 가상 메모리 공간을 만들고, 가상메모리 주소 12345번을 조회하고 싶다면 해당 프로세스의 페이지 테이블에서 frame offset을 제외한 나머지 주소와 페이지 테이블의 물리메모리 시작위치, 프로세스 번호, 세그먼트 번호 등등을 조합해서 가상 메모리가 매핑된 페이지테이블 위치의 물리주소를 알 수 있고 이 물리주소를 알고 있으면 메모리에 flash 방식으로 조회가 가능하죠
flash 방식은 논리회로를 통해서 일괄적으로 동시에 조회하기 때문에 O(1)의 속도로 조회합니다.
물론 page table 1번, 실제 물리주소 1번 해서 총 2번의 물리주소를 접근해야된다는 단점이 있습니다.
hugepage의 장점은 페이지 테이블을 줄여서 TLB에 최대한 많은 양을 저장해서 hit율을 올리는 장점이 있죠
문제는 page단위로 frame을 뭉쳐서 서칭하기때문에 프로세스에 실제 물리메모리 할당을 page 단위로 진행해야합니다.
근데 page 한개가 1G면, 3.1G쓰는 프로세스는 4G(page 4개)를 할당해야되고 900MB는 다른 프로세스들이 쓰지도 못하고 잉여가 되는 거죠, 게다가 hit가 실패했을때 스왑과 교체되는 크기도 매우 클 수 있습니다.
상황에따라 랜덤read/write 등에서 불리할 수도 있습니다. 그렇기 때문에 애플리케이션 수준에서도 충분히 메모리 할당 방식을 최적화했을 때 성능향상을 기대할 수 있습니다.
댓글 감사합니다.
Huagepage 는 애플리케이션에서 언급이 없으면 저도 안씁니다. 이글을 쓰게 된 경우가 MySQL 데이터베이스 때문인데, 문서에 보니 Hugepage 관련 언급이 있어서 찾아보니 page 크기가 크면 일단 성능향상이 있다는 식의 글들이 많이 보여서 의문이 들어서 적게 되었습니다.
Hugepage 크기도 보니까 설정 가능한 값이 있던걸로 기억을 하고 있고 그 크기가 아마도 4M가 아마 Max 값으로 알고 있으나 지금은 어떻게 바뀌었는지 모르겠네요. 하드웨어와 커널 버전도 이제는 달라졌으니 이 글도 이젠 잘 안 맞겠죠.