G1 GC 의 기본적인 목표는 짧은 STW 시간을 가지고 가는 것이다. 어짜피 STW 를 피하지 못할 바에야 이 시간을 짧게 가지고 가는게 유리하다.
여기서 구분해야할는게 있는데 STW 는 Young GC 일때도 발생한다. 하지만 그 시간이 매우 짧아서 못 느낄 정도일 뿐이다. Old GC 의 경우에는 Young GC 대비 STW 시간이 매우 길다. 그 이유는 Heap 메모리 전체를 청소해야하기 때문이며 청소해야할 공간이 클 수록 Garbage Collector 작동을 위한 자원 소모가 많아진다.
다음과 같은 목표를 갖는다.
짧은 STW 시간을 갖도록 한다.
Full GC 가 발생되지 않도록 한다.
여기서 주목해야하는 것이 Full GC 발생하지 않도록 이다.
Full GC 발생 않도록…
MaxTenuringThreshold
이 말은 결국에는 Young GC 만 만들어야 한다는 것을 의미한다. 문제는 live Object 는 결국 최종적으로는 Old Generation 영역으로 이동할 수밖에 없다는데 있다. 그래서 G1 에서는 최대한 Old Generation 영역으로 이동하는 것을 늦출려고 한다. 이에 대한 파라메터가 -XX:MaxTenuringThreshold 다.
-XX:MaxTenuringThreshold: Sets the maximum amount of iterations to keep live objects in the new generation. This defaults to 15.
live 객체를 new generation 에 머물게하기 위한 최대 반복횟수로 번역된다. new generation 에서 Young GC 가 발생하면 오래 살아남을 live 객체를 선별되게 된다. 오래 살아남을 live 객체는 당연히 Old generation 영역으로 이동해야 하는데, 이것을 한번에 판단하지 않겠다는 뜻이다.
적어도 여러번.. 기본값으로 15번 정도는 같은 live 객체가 new generation 에서 생존해 있어야 한다. 그래야 ‘아~ 이놈은 오래 살아남을 놈이구나.. Old Generation 으로 옮기자’ 가 된다.
이러한 메커니즘은 Full GC 를 피하기 위한 것이다. Old Generation 에 live 객체가 많아지면 많아질 수록 Full GC 발생가능성은 커진다. 그래서 왠만하면 Young Generation 에 객체를 머물게하고 Garbage 가 되길 기다린다.
MaxGCPauseMillis – Do not set the new generation size unless required.
이 값을 꼭 지정하도록 하고 있다. G1 은 a pause time-target 을 갖는다. 이값은 MaxGCPauseMillis 로 지정하게 되는데 문제는 이 값을 어떻게든 충족되도록 동작하기 뒤해서 G1은 Young Generation 크기를 자동으로 조정하게 된다.
따라서 반드시 Young Generation 크기를 지정해서는 안된다. 오로지 MaxGCPauseMillis 값을 지정해주고 이를 통해서 자동으로 조정되도록 해야 한다. 200 ~ 500 사이에 값을 지정하면 되는데 될수있으면 그냥 기본값으로 둔다.
G1 에서 추천하는 JVM Options
다음은 G1 에서 추천하는 JVM Options 이다.
JVM Option
Details
-XX:+DisableExplicitGC
기본 추천 옵션으로 명시적 GC 를 사용하지 못하게 한다.
-XX:+UseStringDeduplication
기본값이 disabled 인데, 켜준다. String deduplication 에 대한 메모리 사용을 줄여준다.
-XX:MaxMetaspaceSize
최대 사용가능한 클래스 메타데이터 크기. 네이티브 메모리를 사용한다. 256MB 를 권장하지만 값은 유동적이다.
-XX:MaxTenuringThreshold
기본값: 15. new generation 에 live 객체를 유지하기 위한 최대 반복 횟수. 오랫동안 살아남아야할 live 객체가 많다면 값을 낮추고 그렇지않다면 기본값 사용 권장.
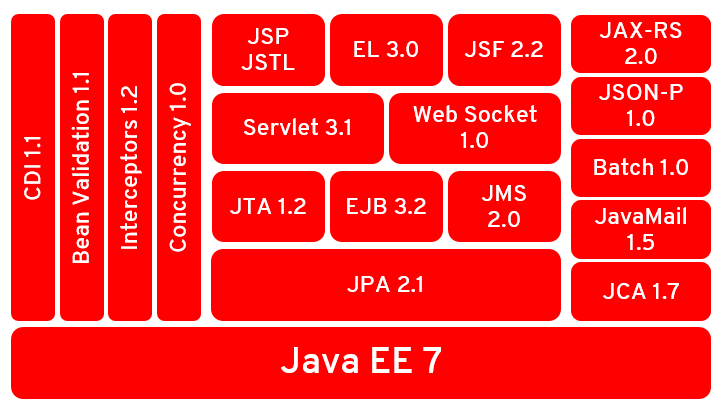
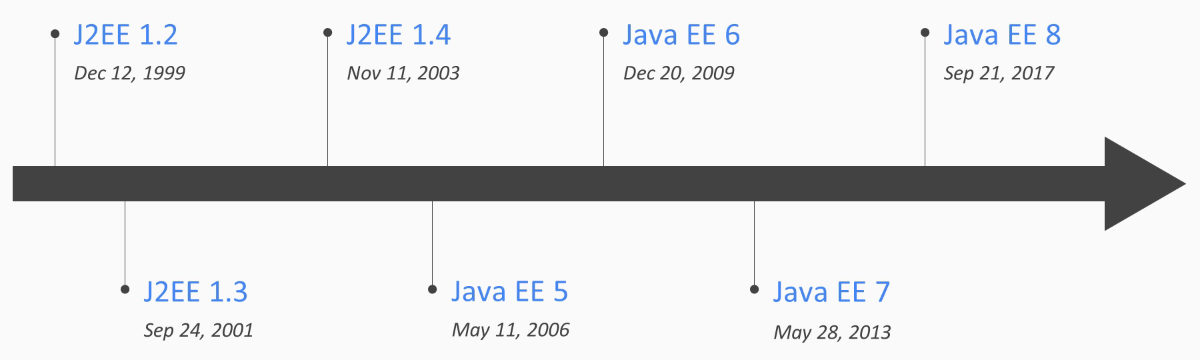
The Jakarta EE 8 has the same set of specifications from Java EE 8 with no changes in its features. The only change is the new process to evolve these specifications. With this, Jakarta EE 8 is a milestone in Java enterprise history, as it inserts these specifications in a new process to boost the specifications to a cloud-native application approach.
자바(Java) 세계에서 언제부터인지 스트림(Stream) 이라는 단어를 목격하게 되었다. 내 기억으로는 Java 8 에서부터 시작된 것 같은데 난데없는 이 단어가 왜 그렇게 핵심이 되었는지가 의문이였다. 도대체 왜 스트림(Stream) 이냐 하는 질문에 대한 대답을 듣기도 어려웠던 시절이기도 하다. 그져 사용하는 방법을 익히는데에 몰두하는 모습만 목격됐을 뿐이다.
java.util.stream
스트림(Stream) 에 대한 정의는 다양하다.
데이터 소스(Array, List) 로부터 흐름을 가지는 데이터의 집합체이며 통합연산을(bulk processing) 통해 데이터를 변형시키고 최종적으로 소비자가 그 데이터를 소비하도록 한다.
스트림을 다루게 되면 항상 다음과 같은 데이터 소스들을 만나게 된다. 모두 데이터의 집합체들이다.
Array
List
하필 왜 데이터 집합체들일까
컴퓨터 알고리즘 필요성과 유사한 스트림(Stream)
난데 없이 컴퓨터 알고리즘을 꺼내온 이유가 있다. 컴퓨터 알고리즘을 공부할때에 가장 먼저 만나는 것이 정렬(sort)문제이다. 그런데, 이런 질문을 하게된다.
왜 하필 정렬부터 인가?
이에 대한 대답은 간단다.
Compute 연산과 Memory 공간을 절약하기 위해서..
컴퓨터가 중복된 데이터를 어떻게 찾아낼까? 정렬을하면 쉽게 해결된다. 정렬된 데이터가 아니라면 모든 데이터를 비교해야 하지만 정렬할 경우에 같은 위상을 같은 데이터 값이 나오게 되는데 이를 하나만 남기고 지우면 간단해 진다.
이렇게 함으로써 Memory 공간도 절약하게 되고 이렇게 중복되지 않은 데이터를 가지고 Compute 연산을 할 경우에 당연히 그에 들어가는 비용도 줄게 된다.
자바에서 스트림도 이와 유사하다.
자바에서 데이터를 다루는 방법은 다양한다. 이는 데이터 소스를 통해서 다루어지는데, 이 데이터 소스를 간단하게 타입(Type) 이라고 생각해보자. 정수형, 문자열 등은 가장 단순한 타입이다.
Primative
1
2
inta=10;
Stringb="systemv";
이런 타입들은 단 하나의 데이터만 저장하고 있을 뿐 “데이터들” 을 가지고 있지 않다. Compute 연산 알고리즘에서는 여러 데이터들의 집합을 다룬다. 컴퓨터가 가지고 있는 데이터들이란 집합을 이야기 한다. 따라서 데이터 소스라고하면 “데이터들” 을 지칭하며 자바에서 이런형태의 데이터 타입은 Array, List 가 대표적이다.
Array
1
2
3
4
5
privatestaticEmployee[]arrayOfEmps={
newEmployee(1,"Amazon",10.0),
newEmployee(2,"MSFT",20.5),
newEmployee(3,"Samsung",30.0)
};
그럼 이런 생각을 하게된다. 데이터 집합체들을 어떻게 하면 빠르게 중복을 제거하고 연산을 하게 만들 것인가? 과거에 For loop 문과 같은 것을 이용해서 조건식을 붙이면서 사용을 할 수도 있다.
람다(Lambda)
연속된 데이터들을 다루기만 할 거라면 단순하게 For loop 문을 이용하면 된다. 만일 이런 생각을 하게 된다.
연속된 데이터를 처리할때에 병렬을 이용해서 처리보자.
For loop 문에서 병렬처리는 쉬운게 아니다. Thread 를 이용할 수도 있지만 이건 동시성 프로그래밍이지 병렬은 아니다.
이를 위해서 자바 8 에서는 람다(Lambda) 를 도입했다. 이것에 대한 정의를 보면 함수형 프로그래밍(Funtional Programming) 이라는 말을 자주 접하게 되는데 병렬연산을 가능하게 하는 부분이다.
자바 8 스트림은 이 람다를 기반으로 한다. 결국에 스트림은 벌크 프로세싱(Bulk Processing) 을 람다를 사용해 구현하여 빠른 고속 데이터 처리가 가능하다.
스트림 – 흐른다.
스트림의 중요한 특징은 흐름이다. 프로그래밍에서 데이터를 다룰때 흐름 없이 다루는 경우도 많다. 앞에서 컴퓨터가 다루는 데이터는 “데이터들” 이라고 했는데, 이것들을 흐름을 가지고 연산을 수행하는게 스트림이다.
“흐른다” 라는 말을 수도관을 떠올리게 한다. 왼쪽에 물을 흘려보내면 오른쪽으로 물이 나온다. 데이터를 왼쪽에서 흘려보내면 오른쪽으로 물이 나온다. 만일 이 물이 설탕물로 만들고 싶다면 중간에 설탕을 뿌리면된다. 이물질을 제거하고 싶다면 이물질 제거기를 설치하면 된다.
이렇게 보면 누군가 데이터를 흘려보내는 놈이 필요하고 데이터를 받아 마시는 놈이 필요하게 된다. 이것을 Producer 와 Comsumer 관계라고 부른다.
리액티브 와 무슨 관계?
자바 스트림과 Reactive 관계보다 차이가 존재한다.
스트림(Stream) 은 데이터를 생산하면 즉각 소비가 발생한다. 하지만 리액티브 는 그렇지 않다. 리액티브 은 시간이 지남에 따라서 생산과 소비가 발생한다. 생산과 소비가 즉각적이지 않다.
이말을 잘 생각해 볼 필요가 있다. 스트림은 데이터를 다루는 영역에서 매우 유용할 수 있다. 프로그래밍 연산을 할 경우에 적합하게 사용되어질 수 있다. 하지만 Reactive 는 프로그래밍 연산보다 네트워크를 통한 데이터 요청과 리턴에 접합한 모델이라고 할 수 있다.
차이는 또 있다. 리액티브 에서 생산자는 반드시 흐름 데이터만 만들지 않는다. 대표적으로 웹에서 클릭(Click) 조차도 리액티브 에서 생산자가 될 수 있다. 그래서 연속된 데이터 흐름이 없다보니 뭔가 생산하는 개념이 아닌것이여서 생산자(Producer) 라는 말을 쓰지 않는다.
“즉각적으로 소비가 발생하지 않는다” 라는 말도 중요하다. 비동기적으로 데이터 리턴이 발생한다는 것을 의미 한다. 하지만 리턴 값을 받기 위한 준비는 항상하고 있다는것도 중요하다.
리액티브 는 네트워크를 통한 데이터 요청, 리턴 모델에 적합하다. 리액티브 요청한 것에 대한 데이터들을 다룰때에는 스트림을 이용할 수도 있다.
Message Request processing failed;nested exception isorg.springframework.transaction.CannotCreateTransactionException:Could notopen JDBC Connection fortransaction;nested exception isjava.sql.SQLException:Cannot create PoolableConnectionFactory(The server timezone value'KST'isunrecognized orrepresents morethan one timezone.You must configure either the server orJDBC driver(via the serverTimezone configuration property)touseamorespecifc timezone value ifyou want toutilize timezone support.)
Description The server encountered an unexpected condition that prevented it from fulfilling the request.
자세히 보면 java.sql.SQLException 이 보인다. 이 경우는 결국에는 데이터베이스쪽에 문제가 있다는 것이며, MySQL을 사용할 경우에 보이게 된다. 이는 MySQL의 시간을 나타내는 타임존 설정이 맞지 않아 생기는 오류다.
MySQL 5.7, MariaDB 10
MySQL 5.7 과 MariaDB 10 을 사용한다면 my.cnf 에서 다음과 같이 설정함으로써 문제 해결이 가능하다.
MySQL 5.7
INI
1
2
#timezone설정
default-time-zone=Asia/Seoul
설정할 수 있는 타임존 리스트는 MySQL 메뉴얼을 참조하기 바란다. 이렇게 했는데도 다음과 같은 오류를 만날 가능성도 있다.
Sometime ago, I found themes of Jeeeyul’s for the Eclipse. But now I can’t find it anywhere in the internet. I have some themes of Jeeeyul’s, so I post it.
이 페이지는 Java 관련 외부 링크를 정리한 것입니다. 훌륭하게 정리한 글들이 넘쳐나고 있는데 이것을 퍼오는것보다 링크를 걸어두는게 더 좋을 것 같아 만들었습니다. 물론 몇몇 글중에는, 내 개인 기준으로 이런게 더 들어갔으면 좋겠다라고 했던 것은 제 블로그에 Post 로 작성하기도 했습니다.